Docker 的使用和 Redis 基础
—— Love98
Docker 的使用和 Redis 基础
在 Windows 上面直接运行 Redis 是一件费力不讨好的事情,因为我们推荐使用容器管理工具 Docker 运行 Redis,在上线运行的项目中,我们也基本采用的是 Docker 部署的方案,所以今天在学习 Redis 之前,我们先了解一下怎么使用 Docker。
About Docker
Docker 是世界领先的软件容器平台,所以想要搞懂 Docker 的概念我们必须先从容器开始说起。
什么是容器
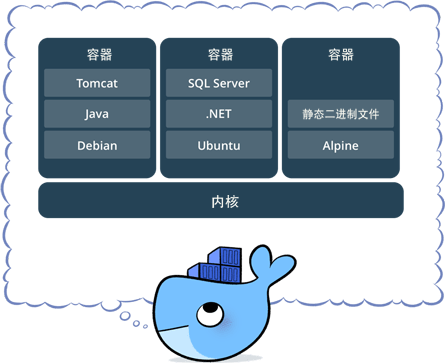
一句话概括容器:容器就是将软件打包成标准化单元,以用于开发、交付和部署。
- 容器镜像是轻量的、可执行的独立软件包 ,包含软件运行所需的所有内容:代码、运行时环境、系统工具、系统库和设置。
- 容器化软件适用于基于 Linux 和 Windows 的应用,在任何环境中都能够始终如一地运行。
- 容器赋予了软件独立性,使其免受外在环境差异(例如,开发和预演环境的差异)的影响,从而有助于减少团队间在相同基础设施上运行不同软件时的冲突。
什么是 Docker
Docker 是世界领先的软件容器平台。
Docker 使用 Google 公司推出的 Go 语言 进行开发实现,基于 Linux 内核 提供的 CGroup 功能和 namespace 来实现的,以及 AUFS 类的 UnionFS 等技术,对进程进行封装隔离,属于操作系统层面的虚拟化技术。 由于隔离的进程独立于宿主和其它的隔离的进程,因此也称其为容器。
Docker 能够自动执行重复性任务,例如搭建和配置开发环境,从而解放了开发人员以便他们专注在真正重要的事情上:构建杰出的软件。
用户可以方便地创建和使用容器,把自己的应用放入容器。容器还可以进行版本管理、复制、分享、修改,就像管理普通的代码一样。
就本节课而言,我们需要知道的只是它运行我们在 Windows/ MacOS 上面运行基于 Linux 的应用,比如 Redis。
Docker 的基本概念
Docker 中有非常重要的三个基本概念,理解了这三个概念,就理解了 Docker 的整个生命周期。
- 镜像(Image) -> 一个特殊的文件系统,在一定程度上就相当于是一个 root 文件系统。
- 容器(Container) -> 容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等*。
- 仓库(Repository) -> 集中存放镜像文件的地方,例如:Docker Registry
安装 Docker-Desktop
Docker Desktop is a one-click-install application for your Mac, Linux, or Windows environment that lets you build, share, and run containerized applications and microservices.
这里我们以 Windows 10 22H2 为例
在安装 Docker 之前,我们需要先做一些准备
CPU 虚拟化
使用虚拟机或者容器化技术,你需要开启 CPU 虚拟化,所以确保你已经开启了CPU虚拟化,如果你没有开启CPU虚拟化,请在BIOS里面开启,具体操作请查询你的电脑主板提供商

WSL 2 or Hyper V
一般而言,WSL 2 的性能比 Hyper V 要更好,但是 WSL 2 相比于 Hyper V 会更加吃内存,准确来说,当你启动 WSL 2 的时候,你的 Windows 上面就已经启动了一台 Ubuntu(默认为Ubuntu),因此如果你的内存大于等于32GB,请选择 WSL 2,否则选择 Hyper V
安装 WSL 2
How to install Linux on Windows with WSL
启用 Hyper V
下载并安装 Docker Desktop
Windows -> Install Docker Desktop on Windows
MacOS -> Install Docker Desktop on Mac
在安装完成之后,对于无法稳定使用魔法的同学,需要进行换源 -> docker-registry-mirrors.md
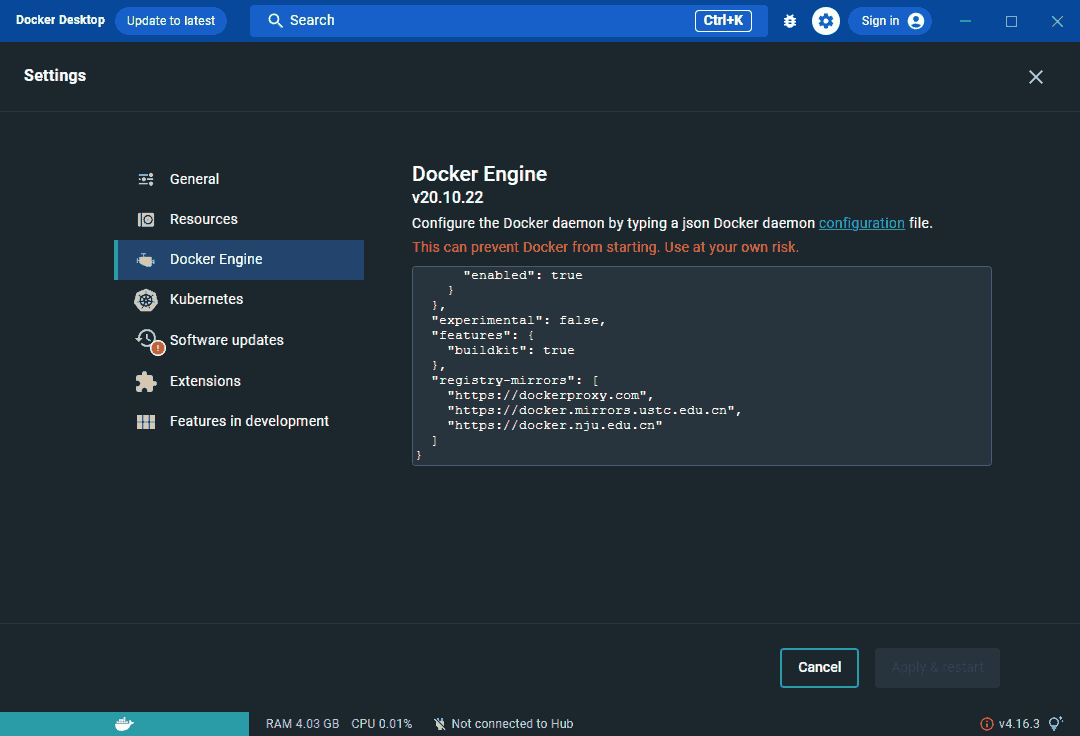
在安装完成之后,你的 Docker Desktop 的设置里面,Docker Engine 选项里面应该是配置文件
打开终端在里面执行 (Linux 需要 root 权限)
1 | docker version |
我得到的输出如下
1 | Client: |
使用 Docker
就我个人而言,我并不觉得 Docker Desktop 很好用,使用它仅仅是因为它省去了在 Windows 上面手动安装 Docker Engine 和 Docker CLI client 的麻烦,在实际开发中,我们依然是围绕终端使用 Docker
打开终端在里面执行 (Linux 需要 root 权限):
1 | docker pull hello-world |
这行命令的意思是:从仓库(Repository)拉取名为 hello-world 的镜像(Image)
1 | docker run hello-world |
这行命令的意思是:创建一个容器(Container)并运行 hello-world 镜像
1 | docker ps -a |
这行命令的意思是:列出所有的容器
让我们回到 docker run hello-world 的输出信息
1 | Hello from Docker! |
这里列出了我们刚刚的操作的原理,也给出了文档的地址
小结
至此,你已经学会了最基本的 Docker 使用,也即使用别人打包好的无交互的镜像
About Redis
Redis (REmote DIctionary Server)是一个基于 C 语言开发的开源 NoSQL 数据库(BSD 许可)。与传统数据库不同的是,Redis 的数据是保存在内存中的(内存数据库,支持持久化),因此读写速度非常快,被广泛应用于分布式缓存方向。并且,Redis 存储的是 KV 键值对数据。
出现背景
- 单机和集群 SQL 服务器压力过大
- 对数据进行冷热区分,并将热数据存储到内存中
Redis 基本工作原理
数据从内存中读写
数据保存到硬盘防止重启数据丢失
增量数据保存到 AOF 文件
AOF (Append Only File): AOF persistence logs every write operation received by the server. These operations can then be replayed again at server startup, reconstructing the original dataset. Commands are logged using the same format as the Redis protocol itself.
全量数据保存到 RDB 文件
RDB (Redis Database): RDB persistence performs point-in-time snapshots of your dataset at specified intervals.
使用单线程处理所有操作命令
为了满足不同的业务场景,Redis 内置了多种数据类型实现(比如 String、Hash、Sorted Set、Bitmap、HyperLogLog、GEO)。并且,Redis 还支持事务、持久化、Lua 脚本、多种开箱即用的集群方案(Redis Sentinel、Redis Cluster)。
Redis 的数据类型
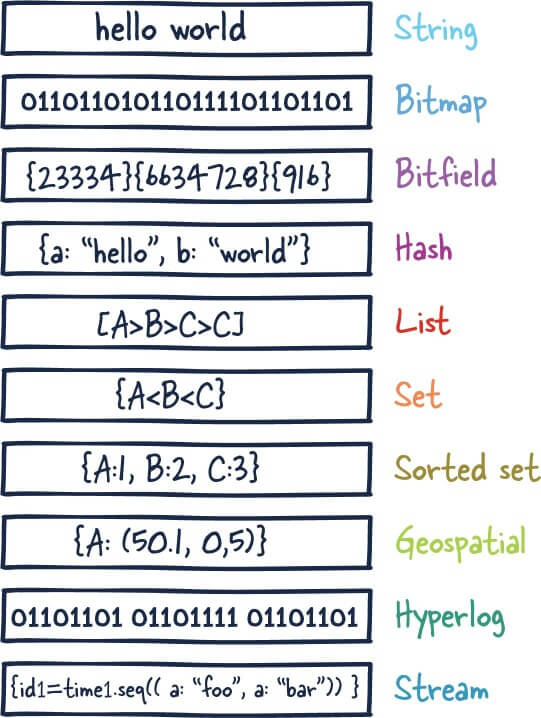
Redis 有5种基本数据类型和3种特殊数据类型,我们只讲5种基本数据类型
| String | List | Hash | Set | Zset |
|---|---|---|---|---|
| SDS | LinkedList/ZipList/QuickList | Dict、ZipList | Dict、Intset | ZipList、SkipList |
String
String 是 Redis 中最简单同时也是最常用的一个数据类型,可以用来存储任何类型的数据比如字符串、整数、浮点数、图片(图片的 base64 编码或者解码或者图片的路径)以及序列化后的对象,这将会是我们只会开发中最常用的数据类型
List
Java 的标准库中内置有 LinkedList,但是 C 语言并没有实现链表,所以 Redis 实现了自己的链表数据结构。Redis 的 List 的实现为一个 双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。
你也可以使用这种数据类型存储队列和栈
Hash
和 Java 的 HashMap 在功能上基本一致,在开发中并不常用
Set
和 Java 的 HashSet 在功能上基本一致
ZSet
和 Set 相比,Sorted Set 增加了一个权重参数 score,使得集合中的元素能够按 score 进行有序排列,还可以通过 score 的范围来获取元素的列表。有点像是 Java 中 HashMap 和 TreeSet 的结合体,它很适合用于实现排行榜等功能
使用 Redis
部署 Redis 服务
在终端中运行以下指令
1 | docker pull redis |
容器名字 -> redis-for-teaching
端口 -> 6379:6379
后台运行
我们使用 Another Redis Desktop Manager 来连接 Redis,使用默认配置即可。

在 Spring Boot 中集成 Redis
引入依赖
在 pom.xml 中添加
1 | <dependency> |
配置序列化器
在 config 目录下创建文件 RedisTemplateConfig.java
并在其中配置序列化器
1 |
|
封装 RedisUtil
来自風楪fy老学长的祖传代码,使用在 SAST 的众多后端项目中 -> RedisUtil.java
Redis 的应用案例
在我们现有的项目中,Redis有以下常用的场景
- 基于 Token 的身份验证或权限验证
- 使用 list 作为消息队列(Redis 官方不推荐大家这么使用,但是在一些小项目里面还是很方便的)
- 热点数据存入 Redis 以减小对 SQL 的压力
- 限流算法:要求1秒内放行的请求为N,超过N则禁止访问
- 排行榜,使用 ZSet 存储数据
Redis 使用的注意事项
Big Key
About Big Key
| Data Type | Big Key Standard |
|---|---|
| String | The byte of the value > 10KB |
| Hash, Set, Zset, list etc. (complex data structures) | The number of element > 5000 | Total byte value > 10MB |
Big Key 的危害
- 读取成本高
- 容易导致慢查询(过期、删除)
- 主从复制异常,服务阻塞无法正常响应请求
业务侧使用 Big Key 的表现
- 请求 Redis 超时报错
消除 Big Key 的方法
拆分
将 Big Key 拆分成 Small Key
Key Value Before article_70011 abcdefghijklmnopuret After article_70011 [70011]abcdef article_70011_2 [70011]ghijklmnop article_70011_3 [70011]uret 压缩
- 将 Value 压缩写入 Redis,读取时解压后再使用
- 选择合适的压缩算法:gzip, snappy, lz4
- 通常情况下,压缩比越高,解压耗时越长
- 需要对实际数据进行测试后,选择一个合适的算法
- 如果存储的是 JSON 字符串,可以考虑使用 Jackson 或 Gson 进行序列化(不要使用 Fastjson ,这个库有安全问题)
集合类数据结构
- 拆分:可以用 hash 取余、位掩码的方法决定放在哪个 Key 中
- 区分冷热:如榜单场景使用 Zset,只缓存前十页数据,后续数据走 DB
Hot Key
About Hot Key
There is no precise definition of a Hot Key. Sometimes when the QPS of a key is bigger than 500, it is a Hot Key.
解决办法
设置 LocalCache
在访问 Redis 之前,在业务侧设置 LocalCache,降低访问 Redis 的 QPS
现成的轮子:
Java -> Guava
Golang -> Bigcache
拆分
将 Hot Key 复制分别写入多个实例,将 QPS 分散在不同是 Redis 实例上,降低负载
这同时也会导致新的问题,更新时需要更新多个 Key,存在数据短暂不一致问题
慢查询
- 批量操作一次性传入多个 KV,建议一次性传入不超过100
- Zset 大部分命令都是 O(log(N)),不建议超过5k
- 操作单 Value 过大
- 对 Big Key 的 expire/delete 操作可能导致慢查询,Redis4.0 之前不支持异步删除 unlink,Big Key 会阻塞 Redis
小结
你已经学会了 Redis 的基本使用,现在是时候用 Redis 优化你的 SAST-Pancake 了